Architecture
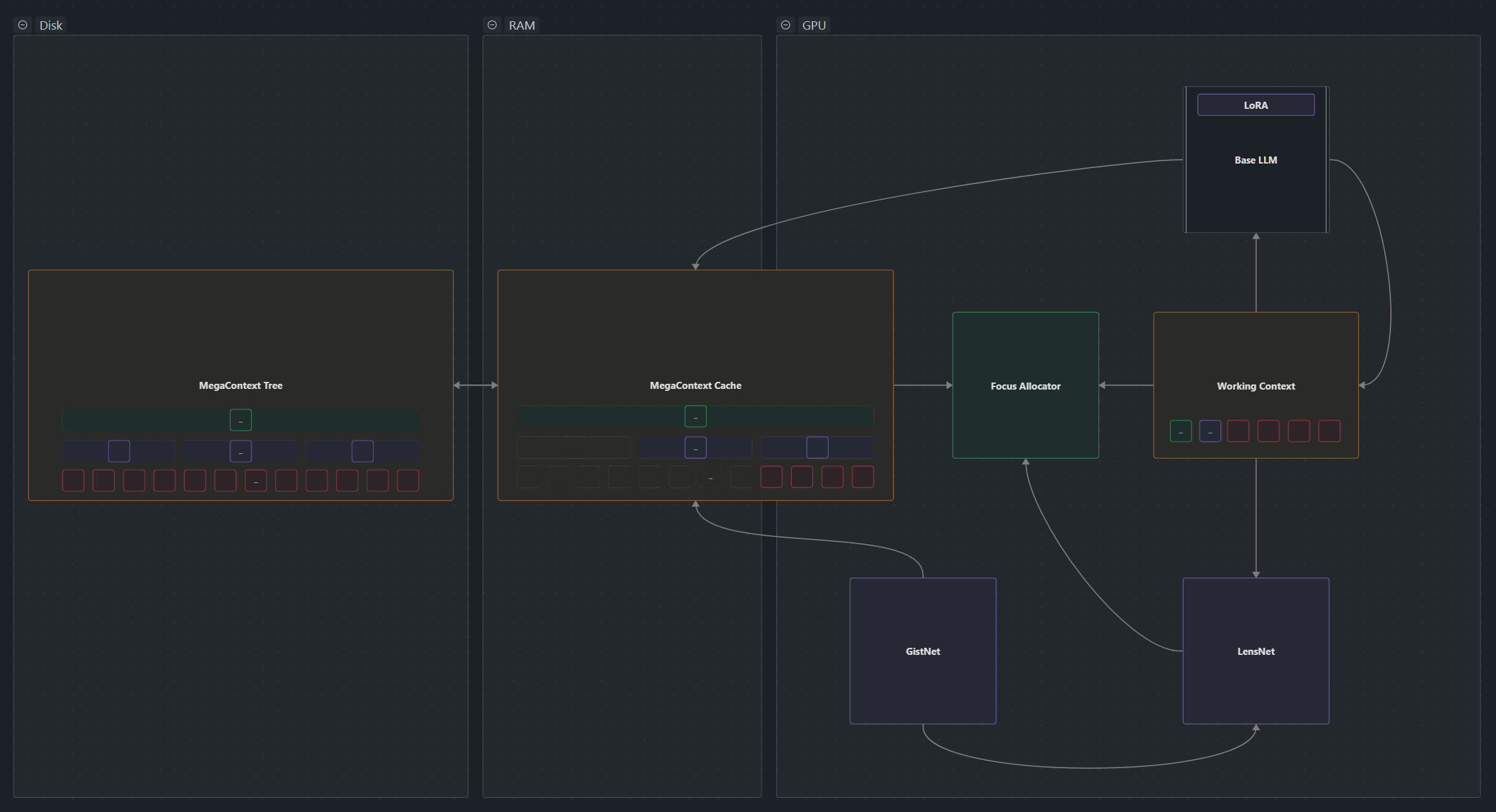 MegaContext separates context into two parts (see Architecture Details for complete explanation): MegaContext Tree (unbounded storage) and Working Context (fixed GPU window). The tree stores complete history as hierarchical gists on disk, while the working context holds a dynamically focused token+gist mix within a fixed budget for inference.
MegaContext separates context into two parts (see Architecture Details for complete explanation): MegaContext Tree (unbounded storage) and Working Context (fixed GPU window). The tree stores complete history as hierarchical gists on disk, while the working context holds a dynamically focused token+gist mix within a fixed budget for inference.
Status: The structures described here reflect the proof-of-concept notebook implementation. Active engineering decisions now flow through the MegaContext PRD Index, and the upcoming nanochat migration will replace the remaining
src/megacontext/...scaffolding. Treat these architecture notes as design references and cross-check the PRDs for the latest contracts.
Architecture Documentation
- Architecture Details
- Two-context architecture, invariants, key terms.
- Explains MegaContext Tree vs Working Context, core Components, update cadence, and invariants.
- POC Architecture
- Module responsibilities, storage layout, sample configs.
- Module table, environment assumptions, binary formats, run configs.
- Runtime Loop
- Ingest → focus → decode pipeline.
- Step-by-step flow (ingest, gist updates, LensNet scoring, Focus Allocator actions, decode, telemetry).
- POC Scope
- guardrails for the proof-of-concept milestone.
- Frozen base model, two-level gist tree, synchronous updates; treat as historical context while current exit criteria live in MegaContext End-to-End Training.