Context Focus
The core insight that MegaContext builds on is that today’s LLMs lack Focus. They have attention, but not focus.
Attention looks at a context all at the same level of detail, and has to determine what information to pay attention to, and which distractors to ignore. It’s very good at doing this, but as contexts get very long with many distractors, attention can start to break down, and get very expensive.
Focus is a concept that is key to the Architecture. MegaContext achieves this by separating context into two parts (see Architecture Details for complete explanation): MegaContext Tree (unbounded storage) and Working Context (fixed GPU window). Focus takes a long context and compresses that information into a smaller mixed-level-of-detail (LOD) shorter Working Context. From there, a normal transformer architecture/base model can operate as usual on the working context.
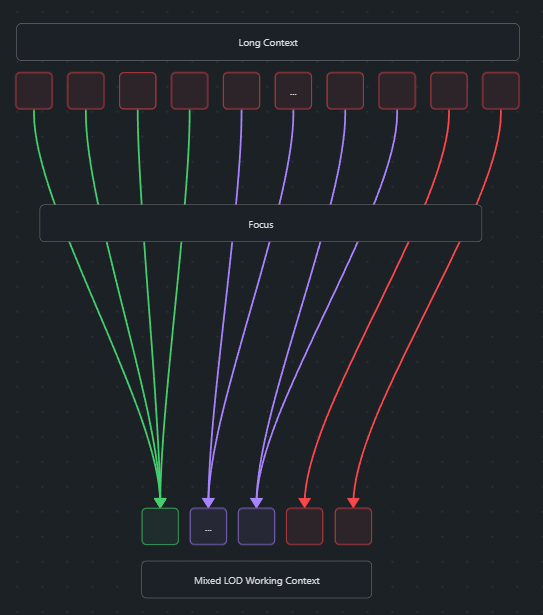 Importantly, with MegaContext is able to do this with sub-linear compute/memory scaling w.r.t. the long context size.
Importantly, with MegaContext is able to do this with sub-linear compute/memory scaling w.r.t. the long context size.
- MegaTexture Analogy
- The inspiration for MegaContext came from graphics tech (1)
- Explains what MegaTexture is, and how it maps to MegaTexture components/features
- How MegaContext Works
- An overview of how MegaContext works
- Explains the problems it solves and how the major components interact
- Glossary
- A glossary of terms related to this project
References
- MegaTexture (Carmack, 2007) — Analysis — Virtual texturing system that inspired the core hierarchical streaming architecture
See Related Work for the complete bibliography of all research papers referenced throughout the documentation.