MegaContext
A system architecture for virtualized hierarchical LLM memory.
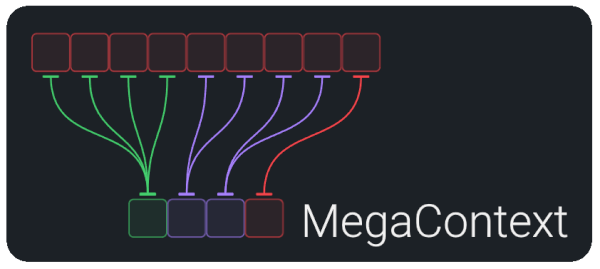
What is MegaContext?
- Two-context architecture: the MegaContext Tree stores the entire history on disk; the Working Context keeps a tiny, on-GPU window.
- Learned controllers: GistNet compresses 32→1, LensNet scores relevance, and the Focus Allocator expands/collapses detail to stay within budget.
- Outcome: effectively infinite memory at constant compute—see How MegaContext Works for the full narrative and diagrams.
The MegaTexture Analogy
MegaContext is inspired by “MegaTexture”, a graphics technology from id Software that virtualized texture memory—streaming visible portions of vast textures at appropriate resolutions. MegaContext applies this same principle to language model context.
See MegaTexture Analogy for the complete explanation.
Why MegaContext Matters
- Long context only helps if the model can focus. MegaContext treats focus as a learned, continuous process rather than a static prompt.
- Resulting capabilities (detail in Grand Vision and Context Focus):
- Persistent memory at constant compute
- Dynamic attention that can re-expand old context when needed
- Smaller, reasoning-focused models whose knowledge lives in the tree
- Agentic workflows and large, updatable “core knowledge” prompts
Quick Start (Today)
- Read: skim this page, then dive into How MegaContext Works.
- Environment: follow
README.md/SETUP.mdfor Python 3.11 + CUDA 12.x prerequisites. - Train: use the matrix in Training & Operations—it’s the source of truth for
run10.sh,speedrun.sh,run1000.sh, telemetry expectations, and troubleshooting. - Evaluate / chat: follow Base Runtime for CLI/web demos once checkpoints land in
~/.cache/nanochat.
Documentation Navigation
There’s a lot of ground to cover—use these hubs to find the level you need:
Orientation
- Context Focus — core intuition
- How MegaContext Works — longer story with diagrams that links out to each component
- MegaTexture Analogy — inspiration from graphics
Architecture & Components
- Architecture Details — two-context contract + invariants
- Components — directory of GistNet, LensNet, Focus Allocator, etc.
- MegaContext Tree, Working Context, Runtime Loop — deep dives on the main subsystems
Plans & Roadmap
- MegaContext PRD Index — current POR (MegaAttention, MegaPrediction, End-to-End Training, Cognitive Core, KV caching)
- Migration Plan - Nanochat Integration / Migration Status — nanochat replatforming
- Future Plan / Grand Vision — longer-term research ideas
Execution & Operations
- Training & Operations, Lifecycle, Base Runtime — nanochat-based training, eval, and runtime guidance
- Telemetry, Performance Sketch, Ops — instrumentation and performance envelopes
Reference
- Glossary — definitions for every term
- Comparisons, MegaContext & RAG — positioning vs. other approaches
- Related Work — bibliography with links to all paper notes
Project Status
Active work now follows the PRD stack rather than the legacy “Phase 0–4” plan. The near-term focus is:
- Implement the POR PRDs (End-to-End Training, MegaAttention, MegaPrediction, Cognitive-Core, Hierarchical KV caching) on top of the landed nanochat fork.
- Scale single-GPU ideas (e.g.,
run10.sh) into the largerspeedrun.sh/run1000.shtrajectories and keep telemetry flowing through tree-aware metrics.
Use the PRD index for requirements and the migration tracker for execution progress.
Contributing
This is an open research project. We welcome contributions that advance the proof-of-concept and the broader vision.
- Follow conventions in
AGENTS.mdfor directory layout, testing, linting, and communication - Bootstrap:
uv venv,uv sync, thenuv run pytest --maxfail=1 --disable-warningsfor smoke tests - Lint/format via
uv run ruff check src testsanduv run ruff format src tests - Update progress in the Obsidian plan notes before hand-off so the next contributor has full context
See the GitHub repository for more details.
MegaContext virtualizes sequence memory just as MegaTexture virtualized textures—focusing detailed computation only where needed. It opens a path to persistent, updatable, and truly lifelong language models.