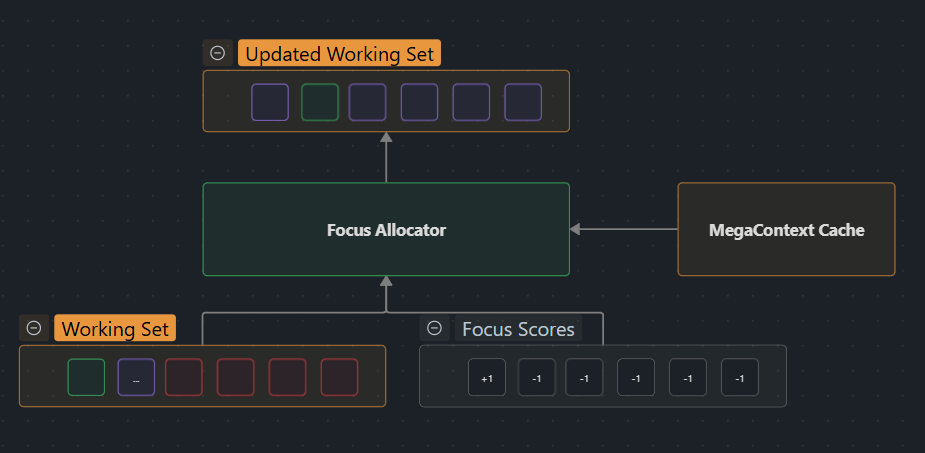
What is the Focus Allocator?
The Focus Allocator is the execution engine that translates LensNet’s utility scores into concrete expand/collapse actions on the Working Context. It operates on block-aligned spans and uses a greedy algorithm with hysteresis to maintain system stability while respecting budget constraints.
Purpose
The Focus Allocator operationalizes focus decisions by:
- Converting LensNet’s signed utilities into legal actions
- Expanding high-utility collapsed blocks (gists → tokens)
- Collapsing low-utility expanded blocks (tokens → gists)
- Maintaining Working Context contiguity and staying within
W_max - Preventing oscillation through cooldowns and guardrails
It bridges the gap between LensNet’s predictions and actual changes to what the base LLM sees.
Core Algorithm Overview
Block-Aligned Operations
The allocator works with 32-token blocks and their gist parents to preserve contiguity, using content-based addressing principles [1]:
- LOD0: 32 raw tokens
- LOD1: Single gist token representing 32 LOD0 tokens
- LOD2+: Hierarchical gists covering 32 children at the previous level
All Working Context entries must cover exactly one full block at a single LOD.
Greedy Loop
The allocator uses a diff-limited greedy approach inspired by learned memory allocation mechanisms [1, 2]:
-
Collect candidates from LensNet scores:
- Positive scores (
> τ_expand) → expand queue (replace gist with tokens) - Negative scores (
< -τ_collapse) → collapse queue (replace tokens with gist) - Filter out illegal actions (violate alignment or budget)
- Positive scores (
-
Rank in priority queues:
- Expands: descending order (highest utility first)
- Collapses: ascending order (most negative first)
- Tie-break by recency or cursor distance
-
Apply actions alternately until:
N_diffactions applied (default: 4 per iteration)- One queue empties
- Next action would exceed
W_max - Collapses refund tokens; expands consume them
-
Optionally re-run LensNet if LOD changes significantly alter utilities (2-3 refinement steps max), similar to iterative attention refinement mechanisms [3]
For detailed strategy variants and future approaches, see Focus Allocator Strategies.
Constraints Maintained
The allocator enforces several critical Invariants:
Budget Control
- Total tokens in Working Context ≤
W_max - Collapses refund token budget; expands consume it
- Net cost drifts trigger corrective bias in next iteration
Hysteresis & Stability
- Action cooldown: Block cannot flip expand↔collapse for
cooldown_stepsiterations (default: 2) - Legality masks: LOD0 blocks cannot expand; root-level blocks cannot collapse
- Consistency checks: Verify entries tile timeline without overlap and siblings share same LOD
Block Alignment
- Every entry covers exactly one block at one LOD
- Siblings at same level must have same LOD
- Prevents mixed LODs that would break contiguity
For complete constraint specifications, see Invariants.
Role in System
The Focus Allocator is the final execution stage in the attention management pipeline:
[[LensNet]] → Focus Allocator → [[Working Context]] Update
↓ ↓
(scores) (expand/collapse)
Integration Points
- Input: Receives per-entry signed utilities from LensNet
- Output: Produces list of expand/collapse operations
- Feedback: Working Context changes flow back to LensNet on next iteration
- Timing: Runs every
Ktokens (default: 32) in sync with LensNet - Advanced variants: In multi-head setups (see Multi-headed Focus), the allocator runs per head with shared invariants while telemetry enforces diversity across windows.
Invariants Enforced
- Maintains Working Context contiguity
- Respects
W_maxbudget constraint - Preserves GistNet block alignment
- Ensures legal LOD transitions
For implementation details, see POC Implementation.
Key Parameters
The Focus Allocator uses several tunable parameters including expansion/collapse thresholds, action limits per iteration, and cooldown periods for stability. For specific values and runtime defaults, see POC Implementation.
Related Pages
Core Dependencies
- LensNet - Provides utility scores
- Working Context - Modified by allocator actions
- GistNet - Defines block structure
- LOD - Level of detail hierarchy
Implementation & Constraints
- Focus Allocator Strategies - Detailed strategy variants and future directions
- POC Implementation - Runtime parameters and integration details
- Invariants - Complete constraint specifications
Related Components
- Working Context Assembly - Initial context construction
- Working Context Refocusing - Overall attention management loop
- MegaContext End-to-End Training - Training regime including allocator behavior
References
- Neural Turing Machines (Graves et al., 2014) — Analysis — Content-based addressing and memory controllers
- Differentiable Neural Computer (Graves et al., 2016) — Analysis — Learned memory allocation and routing
- Slot Attention (Locatello et al., 2020) — Analysis — Object-centric iterative attention mechanism
See Related Work for the complete bibliography of all research papers referenced throughout the documentation.