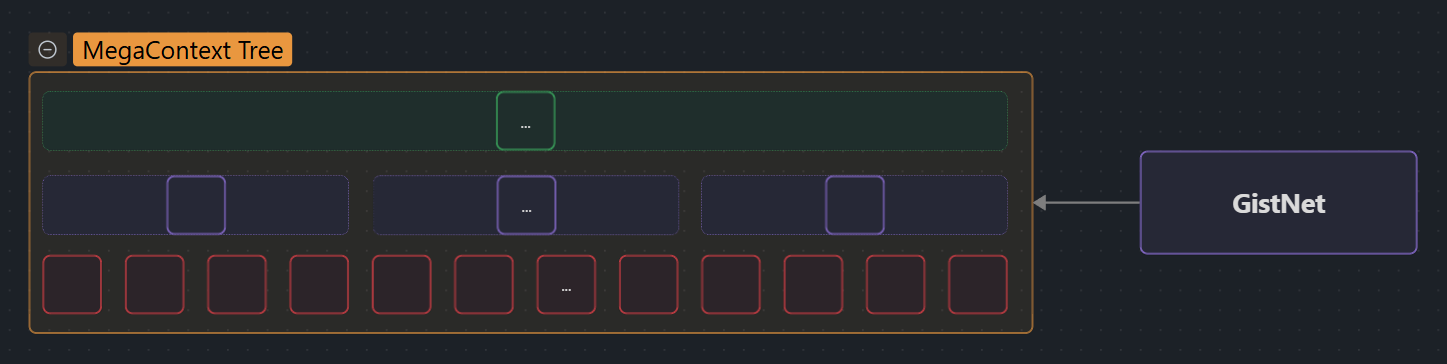
The MegaContext Tree is the complete, append-only history of all tokens and their hierarchical gist summaries [1]. It separates long-term memory (potentially millions or billions of tokens) from the fixed-size Working Context that the base model actually sees.
- Purpose: Store unbounded context history at multiple levels of detail (LOD0, LOD1, LOD2, …).
- Structure: 32-ary tree where each parent gist compresses 32 children (tokens or lower-level gists) [2].
- Storage: Persisted as binary files (
{LOD0,LOD1,LOD2}.ctx) with deterministic offsets. See Storage Format. - Updates: Incremental ingest as 32-token blocks arrive. See Tree Operations.
- Interfaces: Feeds Working Context assembly, LensNet conditioning, and Focus Allocator decisions.
Details
What is the MegaContext Tree?
The MegaContext Tree is a hierarchical data structure that stores the complete interaction or document history as a tree of gists. Unlike traditional LLM context windows that are limited to a fixed size, the MegaContext Tree can grow unboundedly while providing different levels of detail on demand.
Think of it like a pyramid:
- Base layer (LOD0): Every raw token ever seen
- Level 1 (LOD1): Each group of 32 LOD0 tokens compressed into a single gist
- Level 2 (LOD2): Each group of 32 LOD1 gists compressed into a single gist (representing 1,024 LOD0 tokens) [2]
- Level 3+ (future): Additional layers for even coarser summaries
At any moment, the Working Context draws from this tree, selecting which parts to show as raw tokens and which as compressed gists based on LensNet’s focus scores.
Tree Structure & Hierarchy
Node Types
Each node in the MegaContext Tree represents a contiguous span of the original token sequence at a specific level of detail:
| Level | Content | Compression Ratio | Token Coverage |
|---|---|---|---|
| LOD0 | Raw token embeddings | 1:1 (no compression) | 1 token per entry |
| LOD1 | GistNet 32→1 gist | 32:1 | 32 LOD0 tokens |
| LOD2 | GistNet 32→1 gist of gists | 1024:1 | 1,024 LOD0 tokens |
| LOD3+ | (Future) Higher-level gists | 32^n:1 | 32^n LOD0 tokens |
Tree Properties
- Fixed branching factor: Every internal node has exactly 32 children (block size K=32 in POC)
- Perfect alignment: Node boundaries align with 32-token blocks; no partial spans
- Tail safety: If the newest block is incomplete, those tokens remain at LOD0 and behave like “recent tokens” until enough context arrives to form a full block. GistNet never runs on padded inputs.
- Contiguous coverage: Nodes at each level tile the timeline without gaps or overlaps
- Append-only: New tokens extend the rightmost branch; historical nodes are immutable (except for refreshing gists when GistNet is retrained) [3]
- Balanced growth: Tree depth grows logarithmically (log₃₂(N) levels for N tokens)
Example Tree Fragment
LOD2 [0:1024]
├─ LOD1 [0:32]
│ ├─ LOD0 [0] "The"
│ ├─ LOD0 [1] "quick"
│ ├─ LOD0 [2] "brown"
│ └─ ... (29 more LOD0 tokens)
├─ LOD1 [32:64]
│ └─ ... (32 LOD0 tokens)
└─ ... (30 more LOD1 gists)
Block Alignment & Contiguity Invariants
The MegaContext Tree enforces strict block alignment to maintain the Contiguity Invariant:
- Block boundaries: All nodes start and end at multiples of K=32 tokens
- No partial spans: A node never covers 17 or 48 tokens—always exact multiples of 32
- Sibling groups: Every 32 consecutive nodes at level L share the same parent at level L+1
- Timeline coverage: At each level, nodes tile the full token timeline without gaps or overlaps
Why this matters:
- Focus Allocator can swap LOD levels (expand/collapse) without breaking continuity
- RoPE positional encodings [4] remain consistent when gists replace tokens
- Working Context assembly is simplified—just concatenate contiguous node ranges
Relationship to Working Context
The MegaContext Tree and Working Context serve complementary roles:
| Aspect | MegaContext Tree | Working Context |
|---|---|---|
| Scope | Complete history (unbounded) | Fixed window (W_max tokens) |
| Location | Disk (future) or RAM (POC) | GPU memory |
| Content | All levels (LOD0, LOD1, LOD2) stored | Mixed levels selected dynamically |
| Mutability | Append-only, immutable nodes | Entries swap LOD every block |
| Purpose | Long-term memory substrate | Immediate context for base LLM |
Flow:
- All tokens are ingested into the MegaContext Tree
- LensNet analyzes the current Working Context and recent tree state
- Focus Allocator selects which tree nodes to include in the working context and at what LOD
- The working context is a view into the tree, not a separate copy
Role in the System
The MegaContext Tree is the foundational data structure that enables everything else:
- For GistNet: Training data source and storage target for hierarchical gists
- For LensNet: Provides tail gists (recent LOD1/LOD2) used as conditioning signals
- For Focus Allocator: Supplies candidate spans for expand/collapse operations
- For Runtime Loop: Orchestrates ingest → gist → focus → decode cycle
- For telemetry: Tracks access patterns, ΔNLL sensitivity, and pruning signals (see MegaCuration)
Related Pages
Implementation Details
- Storage Format - Binary file layouts, deterministic offsets, memory-mapped I/O strategies
- Tree Operations - Ingest APIs, token buffering, gist generation, and refresh operations
- Node Metadata - Complete metadata schema for tree nodes (span IDs, offsets, versioning)
- POC Implementation - RAM-resident tree, synchronous updates, fixed GistNet checkpoint
Integration Points
- Working Context - How the tree feeds the fixed-size attention window
- GistNet - Neural network that generates hierarchical gist compressions
- LensNet - Conditions on tail gists from the tree for focus scoring
- Focus Allocator - Navigates the tree to select spans and LOD levels
- Runtime Loop - Orchestrates tree updates during inference
System Concepts
- Gists - Compressed embeddings stored at each tree level
- LOD Levels - Hierarchical detail levels in the tree
- Contiguity Invariant - Block alignment guarantees for tree nodes
- MegaCuration - Provenance tracking, pruning, and telemetry (future)
Summary
The MegaContext Tree is MegaContext’s “hard drive”—a persistent, hierarchical memory that stores the complete interaction history at multiple levels of detail. By separating long-term storage (tree) from short-term attention (Working Context), the system achieves effectively infinite context while keeping per-step compute constant. All roads in MegaContext lead through the tree: GistNet builds it, LensNet reads it, Focus Allocator navigates it, and the frozen base model consumes refined views drawn from it.
References
- MegaTexture (Carmack, 2007) — Analysis — Virtual texturing system that inspired the core hierarchical streaming architecture
- Compressive Transformer (Rae et al., 2019) — Analysis — Long-term compressed memory for transformers
- Transformer-XL (Dai et al., 2019) — Analysis — Segment-level recurrence and relative positional encoding
- RoPE (Su et al., 2021) — Analysis — Rotary position embeddings used throughout MegaContext
See Related Work for the complete bibliography of all research papers referenced throughout the documentation.