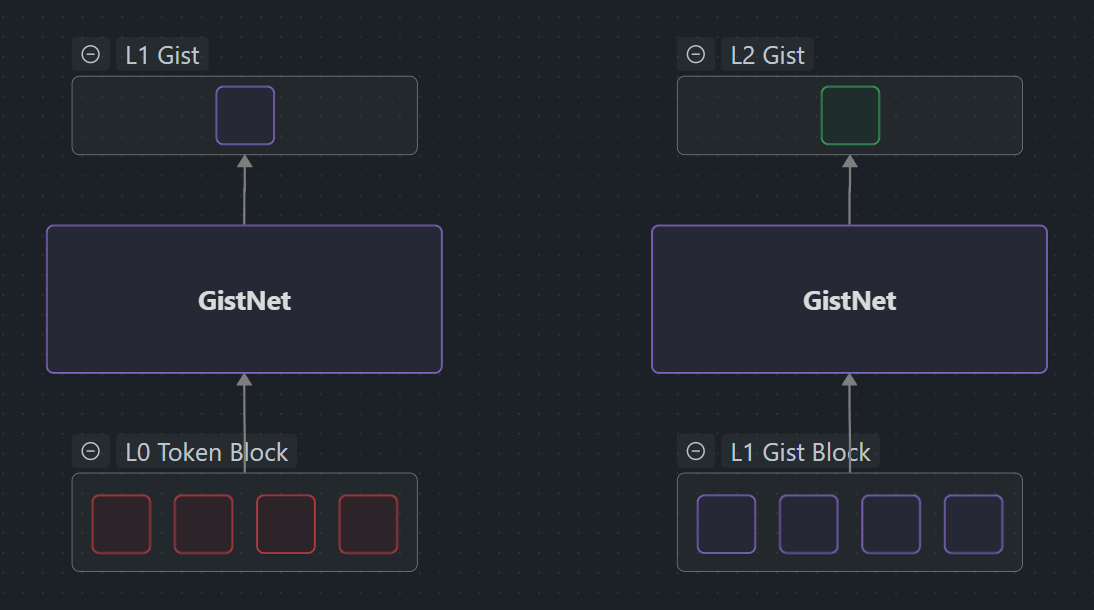
GistNet compresses each 32-token block into a single gist embedding aligned with the base model’s hidden space, enabling substitutable multi-level representations inside MegaContext.
What is GistNet?
GistNet is a local encoder for token spans that replaces fixed-length token sequences with compact gist embeddings (“gists”) [1]. Each gist preserves the meaning of its original tokens while freeing Working Context budget for new information. The key innovation is substitutability [1]: gists can stand in for their original tokens inside the base LLM’s context with minimal impact on predictions.
Purpose
- Replace raw tokens with substitutable gists to free context budget.
- Enable compression of 32 tokens → 1 gist at each level of the MegaContext Tree.
- Hierarchical stacking provides 1024× compression (32² with two levels).
- Align embeddings with the base model’s embedding space for seamless substitution.
Architecture Snapshot
GistNet now uses a lightweight stack of nanochat transformer blocks on top of a 32-token window. Pooling heads collapse the final activations into a single gist without modifying the backbone.
flowchart LR Tokens[32 token embeddings] CLS[(optional CLS token)] Blocks[Mini transformer blocks<br/>(RoPE + MHA + MLP)] Head[Pooling head<br/>(mean · query · CLS)] Gist[gist ∈ ℝ^d] Tokens --> Blocks Tokens -. prepend .-> CLS --> Blocks Blocks --> Head --> Gist
- Embedding + RoPE. The 32-token slice is embedded and rotated with local RoPE metadata.
- Mini transformer stack. 1–N nanochat blocks (attention + MLP) process the window. Heads share weights across all spans; adding a
[CLS]token is optional per head. - Pooling head. We collapse the per-token states via one of three readouts:
- Mean pooling + linear or MLP projection (baseline).
- Query pooling: a learned query attends to the window once (Structured Self-Attentive pooling [4]).
- CLS pooling: prepend a learnable
[CLS]token and read it directly (BERT-style [5]).
Current Code Path
We expose each design axis directly via CLI flags:
| Flag | Values | Notes |
|---|---|---|
--block_size | 8, 32 (default), 128 | Tokens per gist block; affects tree depth and cost. |
--gistnet_type | transformer (default), mean | “mean” uses the simple pooling baseline. |
--gistnet_layers | 2 (default), 4 | Transformer depth per block. |
--gistnet_pooling | mean (default), query, cls | Pooling strategy before the scoring head. |
--gistnet_head | mlp (default), linear | Projection after pooling (mean pooling uses MeanMLP/MeanLinear; query/cls heads share the same projection type). |
The legacy self-attention/slot variants were removed—only the transformer stack + pooling heads remain in code.
Workflow in MegaContext
- Encode span. The per-device embedding layer produces
[B, 32, d]slices for each token block. - Run GistNet. The mini transformer + pooling head outputs a gist
[B, 1, d]. - Insert gist. The MegaContext Tree stores the gist at LOD0 and higher, reducing on-device context size.
- Hierarchical stacking. Re-run GistNet on sets of 32 gists to obtain higher LOD nodes (32² compression).
- Focus loop. LensNet scores the resulting gists, and the Focus Allocator decides when to expand or collapse them.
Training Summary
Training still minimizes ΔNLL@H using a frozen teacher LLM:
- Sample a random 32-token window.
- Run GistNet → gist.
- Replace the window with the gist in-context.
- Teacher runs on original vs. gist context, providing logits for KL/ΔNLL.
- Optional contrastive term keeps neighbouring gists distinct.
See GistNet Training for objectives, loss weights, and optimizer settings.
Inputs & Outputs
| Symbol | Shape | Meaning |
|---|---|---|
E ∈ ℝ^{32×d} | Raw token embeddings from the base model | |
CLS ∈ ℝ^{d} | Optional learnable summary token (CLS pooling only) | |
g ∈ ℝ^{d} | Final gist vector aligned with the base model |
Related Pages
- GistNet Training — Training objectives, loss functions, and pipeline.
- GistNet Architecture Details — Deep dive into transformer blocks, pooling heads, and complexity.
- MegaContext Tree — Hierarchical storage for multi-level gists.
- LensNet / Focus Allocator — Consumers of gists during focus allocation.
- Training & Operations — End-to-end training orchestration.
References
- Gist Tokens (Mu et al., 2023) — Analysis — Learned prompt compression via attention masking.
- Compressive Transformer (Rae et al., 2019) — Analysis — Long-term compressed memory for transformers.
- Knowledge Distillation (Hinton et al., 2015) — Analysis — Teacher-student framework for GistNet training.
- Structured Self-Attentive Sentence Embedding (Lin et al., 2017) — Analysis — Query-based pooling inspiration.
- BERT (Devlin et al., 2018) — Analysis — CLS token pooling inspiration.
See Related Work for the full bibliography used across the MegaContext documentation.