How MegaContext Works
MegaContext virtualizes sequence memory for language models—enabling effectively infinite context at constant compute. This note provides a narrative walkthrough of the complete system.
Reading map: If you just need the elevator pitch, start with the landing page. When you’re ready for API/implementation details, jump to Architecture Details and the component notes under
obsidian/architecture/components/. The sections below keep the story in one place but link out to the single sources of truth so we avoid duplication.
The Problem: Fixed Context Windows
Standard LLMs have a fundamental limitation:
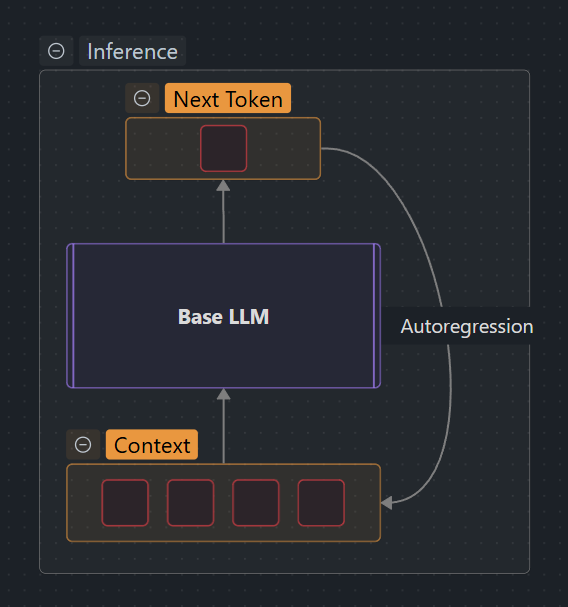
Traditional LLM context is fixed:
- Most models support 4k–32k tokens
- Older context gets evicted when the window fills
- No way to zoom in/out on different parts
- Everything is at the same level of detail
Problems this causes:
- Long conversations get truncated
- Important earlier context is lost forever
- Can’t distinguish between “critical details” and “background noise”
- Memory grows linearly with context length (GPU RAM limits)
- Compute grows quadratically with attention (O(n²) complexity)
The MegaContext Solution: Virtual Memory for LLMs
MegaContext solves this by separating long-term storage from active attention, just like a computer’s virtual memory separates disk from RAM [1].
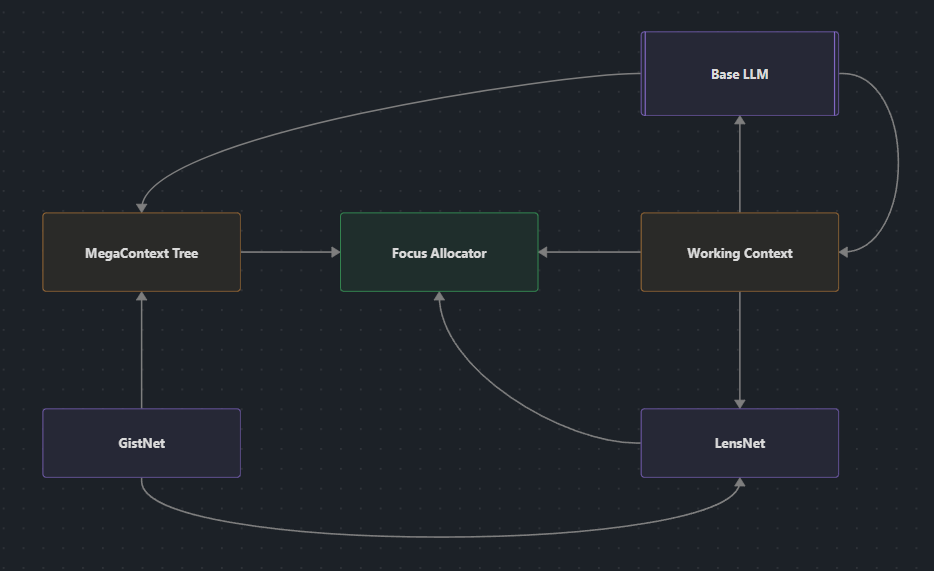
Two-Context Architecture
MegaContext maintains two separate contexts:
1. MegaContext Tree (Long-term Storage)
- Location: Disk (or RAM in POC)
- Size: Unbounded—can grow to millions or billions of tokens
- Content: Complete interaction history stored as a hierarchical tree of gists
- Structure: 32-ary tree with multiple levels of detail (LOD0, LOD1, LOD2, …)
- Role: The “hard drive” of memory
2. Working Context (Active Attention)
- Location: GPU memory
- Size: Fixed budget (W_max = 8k–32k tokens)
- Content: Mixed levels of detail—raw tokens where needed, gists elsewhere
- Structure: Contiguous sequence of entries drawn from the tree
- Role: The “RAM” that the base LLM actually sees
See Architecture Details for the complete two-context design and invariants.
The Core Insight: Hierarchical Compression
Instead of storing everything at the same resolution, MegaContext builds a hierarchy of summaries:
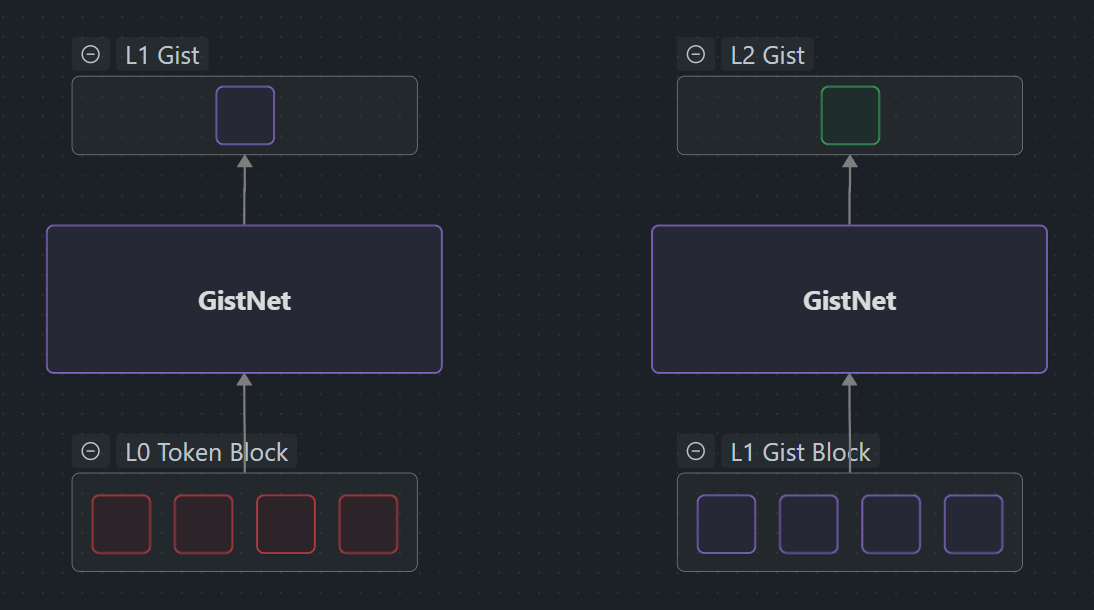
Level 0 (LOD0): Raw Tokens
"The quick brown fox jumps over the lazy dog near the riverbank"
Every individual token at full detail—highest cost, highest fidelity.
Level 1 (LOD1): 32→1 Gist
[gist: "narrative about fox movement near water"]
32 tokens compressed into a single learned embedding by GistNet—32× compression.
Level 2 (LOD2): 32→1 Gist of Gists
[gist: "outdoor animal scene collection"]
32 LOD1 gists compressed into one LOD2 gist—1024× total compression.
Key property: Substitutability
- Gists are trained to be drop-in replacements for their tokens
- When a gist replaces its tokens, the model’s predictions barely change (low ΔNLL@H)
- This lets the working context swap between detail levels without breaking coherence
Component quick reference
| Component | Role | Go deeper |
|---|---|---|
| GistNet | Compresses 32-token blocks into gists so history fits in the tree. | GistNet Architecture Details, GistNet Training |
| LensNet | Scores each working-context entry with a focus score so we know where to add/remove detail. | LensNet, LensNet Scoring, LensNet Training |
| Focus Allocator | Converts scores into legal expand/collapse actions while staying within W_max. | Focus Allocator, Focus Allocator Strategies |
| Runtime Loop | Orchestrates ingest → refocus → decode, feeding the frozen base LLM. | Runtime Loop, Training & Operations |
The Four Core Components
1. GistNet: Compression in 32-token bites
GistNet is the learned compressor that turns every 32-token block into a single gist so the MegaContext Tree can grow without exploding. That’s the only detail you need from this page; the actual network, losses, and training loops live in GistNet, GistNet Architecture Details, and GistNet Training.
2. LensNet: The focus controller
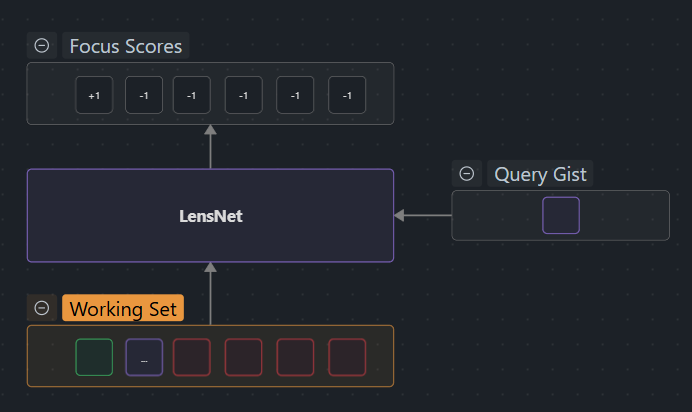
LensNet runs a Perceiver-style cross-attention over the Working Context plus a few tail gists so it can emit signed focus scores for every span. Positive scores mean “expand this region,” negative scores mean “collapse it.” Details such as architecture, scoring math, and counterfactual supervision belong in LensNet, LensNet Scoring, and LensNet Training—this doc stays focused on what LensNet provides (a learned policy) rather than how it’s implemented.
3. Focus Allocator: Turning scores into actions
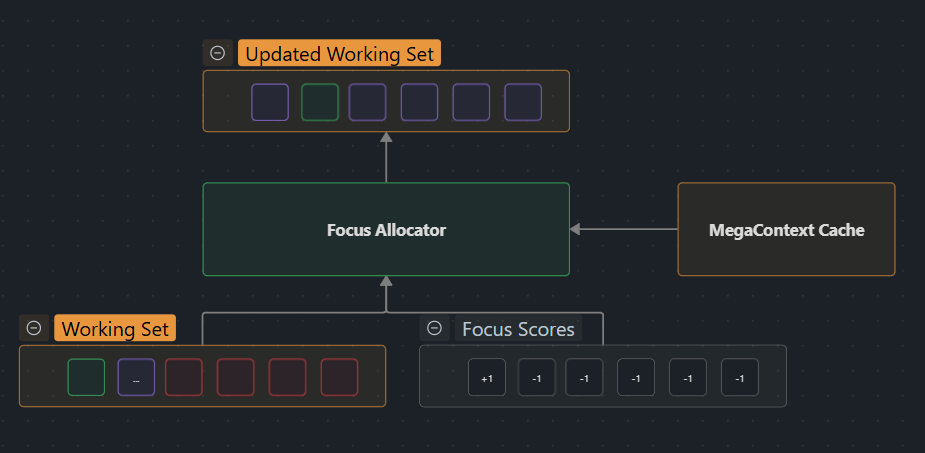
LensNet only makes recommendations. The Focus Allocator is the discrete controller that keeps the working context legal: it enforces W_max, preserves block alignment, and throttles oscillations while applying each expand/collapse action. The current greedy strategy (and future variants) are documented in Focus Allocator and Focus Allocator Strategies—refer there for the algorithm; treat this paragraph as the conceptual glue.
4. Runtime Loop: The orchestrator
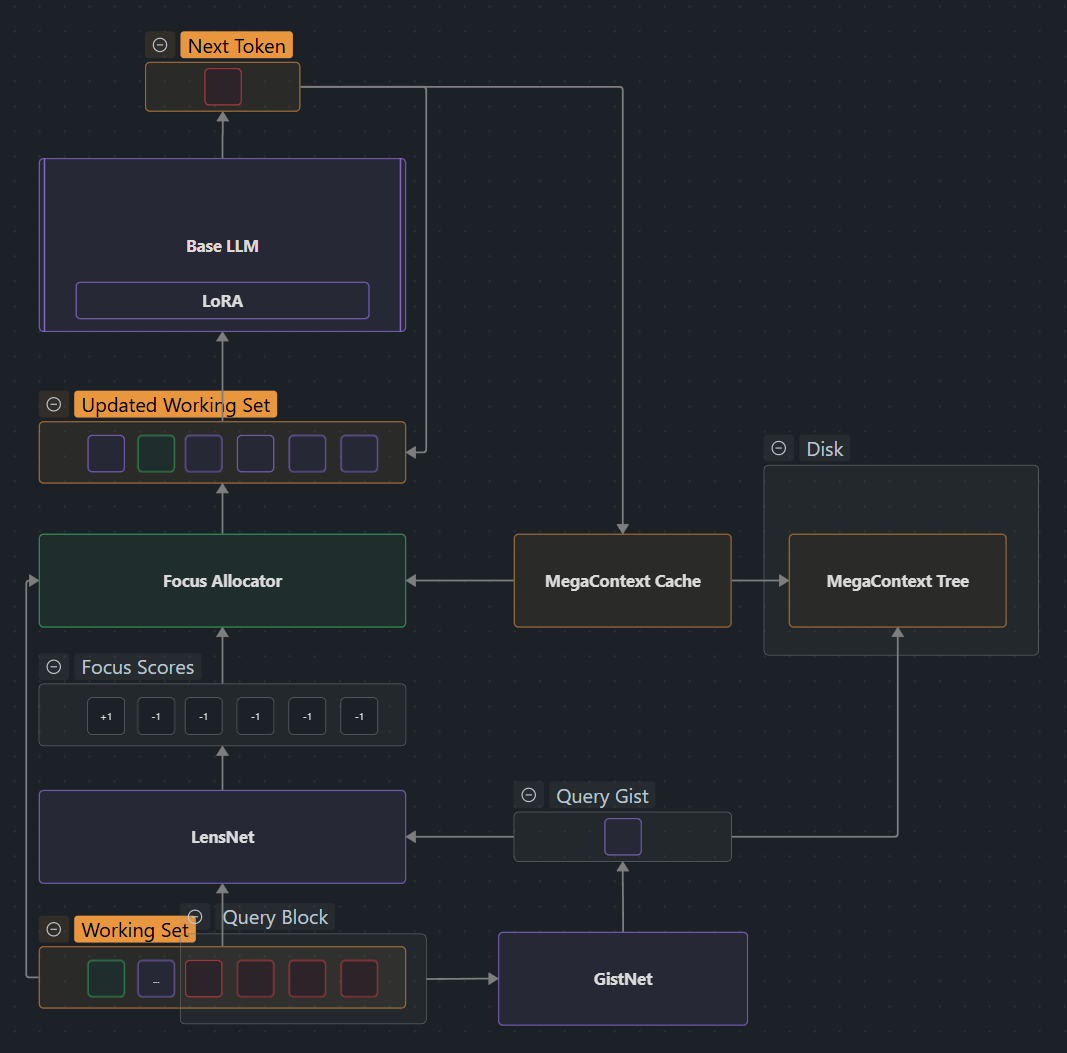
All of this runs inside a per-block loop: ingest new tokens with GistNet, assemble the Working Context, let LensNet + Focus Allocator refocus it, then feed the result through the frozen base LLM and log telemetry (ΔNLL, swap rate, access count). Implementation specifics, nanochat hooks, and training cadence are covered in Runtime Loop and Training & Operations; this section just explains how the pieces interleave.
Real-World Example
Want to see how this works in practice? See Examples for a detailed walkthrough of a coding session that shows how LensNet and the Focus Allocator automatically shift detail levels as the user’s attention moves between different parts of a codebase.
Key System Properties
MegaContext achieves effectively infinite context at constant per-token cost with sub-linear memory growth. The system provides dynamic learned focus (not retrieval) and works with any pretrained LLM without fine-tuning. For example, per-step compute matches the base model decode with only ~1% overhead, while the Working Context stays fixed at W_max regardless of total history length.
See System Properties for complete analysis of constant compute, sub-linear memory, dynamic focus, and model-agnostic design, plus Performance Sketch for detailed compute/storage envelopes.
Comparison to Alternatives
How does MegaContext differ from standard LLMs, RAG, or other approaches?
vs. Standard LLMs: Unbounded vs fixed context, constant vs quadratic compute, compressed vs lost history
vs. RAG [4]: Inline gist substitution vs external retrieval, continuous refocusing vs query-time search, persistent evolving memory vs stateless chunks
See Comparisons for detailed comparison tables and MegaContext & RAG for RAG-specific analysis.
Current Status
We’re now executing the MegaAttention/MegaPrediction PRD stack rather than the legacy POC milestone:
- ✅ Repository & tooling setup + nanochat CLI integration
- 🔄 MegaContext End-to-End Training small-model runs (GistNet + LensNet + base co-training)
- 🔄 MegaAttention Training prototype kernels + KV cache strategy
- 🔄 MegaPrediction Training multi-LOD readouts wired into runtime
- ⏳ Cognitive-Core Training + evaluation harnesses
See MegaContext PRD Index for the active roadmap, POC Scope for historical constraints, and POC Implementation for nanochat-oriented runtime details.
Learn More
Core Architecture
- Architecture Details — Two-context design, invariants, key terms
- MegaContext Tree — Hierarchical gist tree structure and storage
- Working Context — Fixed-size GPU window and refocusing
- Invariants — System guarantees and constraints
- Storage Format — Serialization and disk layout
Components Deep Dives
- GistNet — Overview and training
- GistNet Architecture Details — Network structure
- GistNet Training — Loss functions and optimization
- LensNet — Overview and focus control
- LensNet Scoring — Score computation mechanics
- LensNet Training — Counterfactual labeling
- Focus Allocator — Overview and planning
- Focus Allocator Strategies — Algorithm details
- Tree Operations — Expand/collapse mechanics
- Working Context Assembly — Context construction
- Working Context Refocusing — Dynamic adjustment
- Node Metadata — Tree node data structure
Operations & Training
- Runtime Loop — Ingest → focus → decode cycle
- Training & Operations — Training overview
- MegaContext End-to-End Training — GistNet/LensNet training cycles
- Telemetry — Logging and metrics
- Performance Sketch — Compute and storage analysis
Vision & Extensions
- Grand Vision — Long-term goals and research directions
- MegaPrediction — Speculative planning in gist space
- MegaCuration — Learned pruning strategies
- Cognitive Core — Reasoning models backed by MegaContext
Reference
- Comparisons — Detailed comparison tables
- MegaContext & RAG — RAG-specific analysis
- Related Work — Academic context and prior art
Summary
MegaContext virtualizes LLM context through three key innovations:
- Hierarchical compression (GistNet) — Store history at multiple resolutions
- Learned dynamic focus (LensNet + Focus Allocator) — Automatically adjust detail levels
- Two-context architecture — Separate unbounded storage (MegaContext Tree) from fixed attention (Working Context)
The result: effectively infinite context at constant compute, with automatic memory management and learned relevance detection. It’s not about making context windows longer—it’s about making them smarter.
References
- MegaTexture (Carmack, 2007) — Analysis — Virtual texturing system that inspired the core hierarchical streaming architecture
- Perceiver (Jaegle et al., 2021) — Analysis — Latent cross-attention bottleneck architecture
- Perceiver IO (Jaegle et al., 2021) — Analysis — Query-based decoding for arbitrary structured outputs
- RAG (Lewis et al., 2020) — Analysis — Retrieval-augmented generation baseline
- Gist Tokens (Mu et al., 2023) — Analysis — Learned prompt compression via attention masking
- LLMLingua-2 (Pan et al., 2024) — Analysis — Task-agnostic prompt compression via token classification
- Compressive Transformer (Rae et al., 2019) — Analysis — Long-term compressed memory for transformers
- Neural Turing Machines (Graves et al., 2014) — Analysis — Content-based addressing and memory controllers
See Related Work for the complete bibliography of all research papers referenced throughout the documentation.