 MegaContext treats Context Focus as the organizing principle: GistNet compresses, LensNet scores, and the Focus Allocator trades detail for budget inside the Working Context. This note outlines two extensions under exploration that push focus beyond a single view: Multi-Head Focus and Staging Contexts.
MegaContext treats Context Focus as the organizing principle: GistNet compresses, LensNet scores, and the Focus Allocator trades detail for budget inside the Working Context. This note outlines two extensions under exploration that push focus beyond a single view: Multi-Head Focus and Staging Contexts.
Focus as the core abstraction
- The system’s power comes from selecting where detail lives, not just how much context we can store.
- Traditional attention attends over every token equally; MegaContext focuses detail and then reuses standard transformer attention on a smaller, higher-value window.
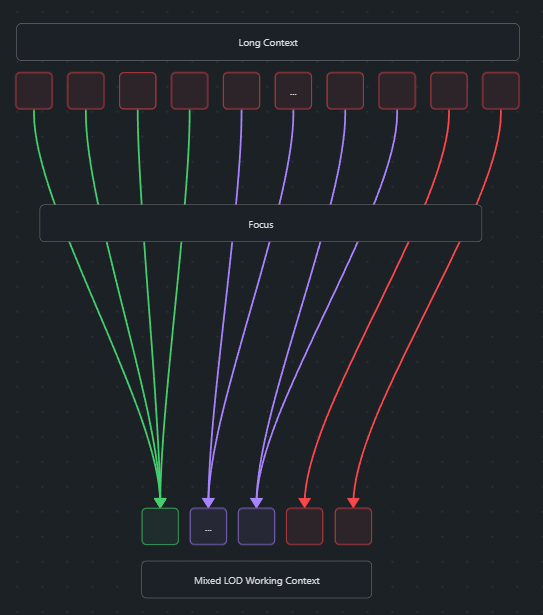
- Multi-headed focus mirrors multi-headed attention: multiple perspectives over the same lifetime history, each emphasizing different span types before the base model runs.
Multi-Head Focus (MHF)
Goal: Maintain several small working contexts that differ primarily in their level-of-detail (LOD) allocation, giving the base model multiple tailored views.
Concept
- Start from the shared MegaContext Tree.
- Assemble
Hworking contexts (WC₁ … WC_H), each capped at ~2k–4k entries. - Use a shared LensNet backbone with head-specific adapters or prompts to emit focus scores tailored to different cues (e.g., entities, locations, analogy spans).
- The Focus Allocator runs per head, yielding distinct LOD layouts.
- Run the frozen base model on a chosen subset of heads.
Motivations
- Relative compute savings: Multiple small windows can outperform one very large window if specialised focus reduces redundancy.
- Perspective diversity: One head can devote budget to recency, another to rare but relevant episodes, etc.
- MoF (Mixture-of-Focus) routing: Instead of always running every head, we can train a router that picks the top-k heads given the current query embedding and LensNet score statistics.
Design considerations
- Shared LensNet backbone: keeps training affordable and scales with the number of heads. Head identity is injected via lightweight adapters or learned prompts.
- Focus diversity incentives: telemetry can penalize overlapping LOD0 spans across heads, or reward heads that surface novel details.
- Merging outputs: combine final hidden states (not logits) through a learned merger or weighted average, then run the LM head once to avoid repeated disembedding.
- Telemetry: log ΔNLL improvements per head vs. compute cost to evaluate whether extra heads pay off.
Staging Contexts
Goal: Insert a large intermediate context (e.g., 100k entries) between disk-backed MegaContext and the small working contexts to give LensNet richer temporal coverage before specialising.
Role
- Acts as a high-resolution reservoir that is not fed to the base model directly.
- LensNet-G (global) periodically refocuses the staging context, ensuring strong candidates are present for downstream heads.
- Smaller working contexts draw from the staging context but can fetch outside it when they need finer LOD coverage.
Update cadence
- Staging context refreshes less frequently than the per-head updates (e.g., every few hundred tokens).
- Per-head LensNet passes use the latest staging view but retain autonomy in choosing detailed spans.
Benefits & open questions
- Sharper focus decisions: larger temporal context offers more evidence before compressing to small windows.
- Compute amortization: the expensive wide LensNet pass runs occasionally; small-head updates stay cheap.
- Alignment challenges: staging must maintain invariants (contiguity, budget) and expose metadata so heads can safely refine or bypass it.
Research roadmap
- Prototype MHF without staging to measure baseline gains and train routing strategies (static mix, utility-gated, learned router).
- Instrument coverage telemetry to validate diversity heuristics and determine optimal head counts.
- Explore staging layers once MHF infrastructure exists, layering LensNet-G on top of the shared backbone.
- Integration experiments: compare single 100k-window baselines against multi-head/multi-stage setups for accuracy vs. wall-clock trade-offs.
Related documentation
- LensNet — focus scoring model extended by head-specific adapters.
- Focus Allocator — execution engine that applies per-head focus plans.
- Working Context — details on budgeted windows that MHF manipulates.
- Positional Encoding — describes how global indices stay consistent when multiple windows co-exist.